Motivation
Coming off of the Microservices in .NET reading, I realized that going through textbooks like I’ve done for the past ~year may not cut it anymore. I think that the time spent reading and taking notes on a textbook may be better spent either reading the actual code of the project or documentation of the used libraries, or just actually writing my own code. It feels like I spent a lot of time just to re-discover the advice that’s been touted by anyone that’s ever written a “how to become a software developer” article: make your own projects.
That being said, I don’t particularly consider myself very creative, and the few ideas I do have don’t particularly relate to the topics I’m trying to learn at the moment (currently microservices, Docker, and Kubernetes). So, I’ve taken a middle path and decided upon the following: implementing various system design projects. Right now, I want to work through the System Design Primer, but I’ll consider other resources as well. Upon closer inspection, this idea seems to tick a lot of the boxes I was looking for in a project, as well as provide some unintended bonuses:
- A relatively short turnaround time. I find that tight feedback loops make for better learning rather than working on something for an extended period of time.
- These projects don’t require spending too much time obtaining domain knowledge.
- The requirements, not the implementation are given, meaning I get to write most of the code myself.
- These systems often have multiple parts, making them good for practicing microservices, Docker, and Kubernetes.
- These systems make use of several different technologies like message queues and caches.
- I get practice for things that I’ll encounter later on in my career.
Overview
I’ll mainly borrow the requirements set out in the System Design Primer, but I’ve found other resources describing this project as well.
My implementation follows closely to the one outlined in the System Design Primer, with a few modifications and ideas taken from other descriptions of the project. The basic high-level design looks pretty much the same as in the System Design Primer (click to enlarge):
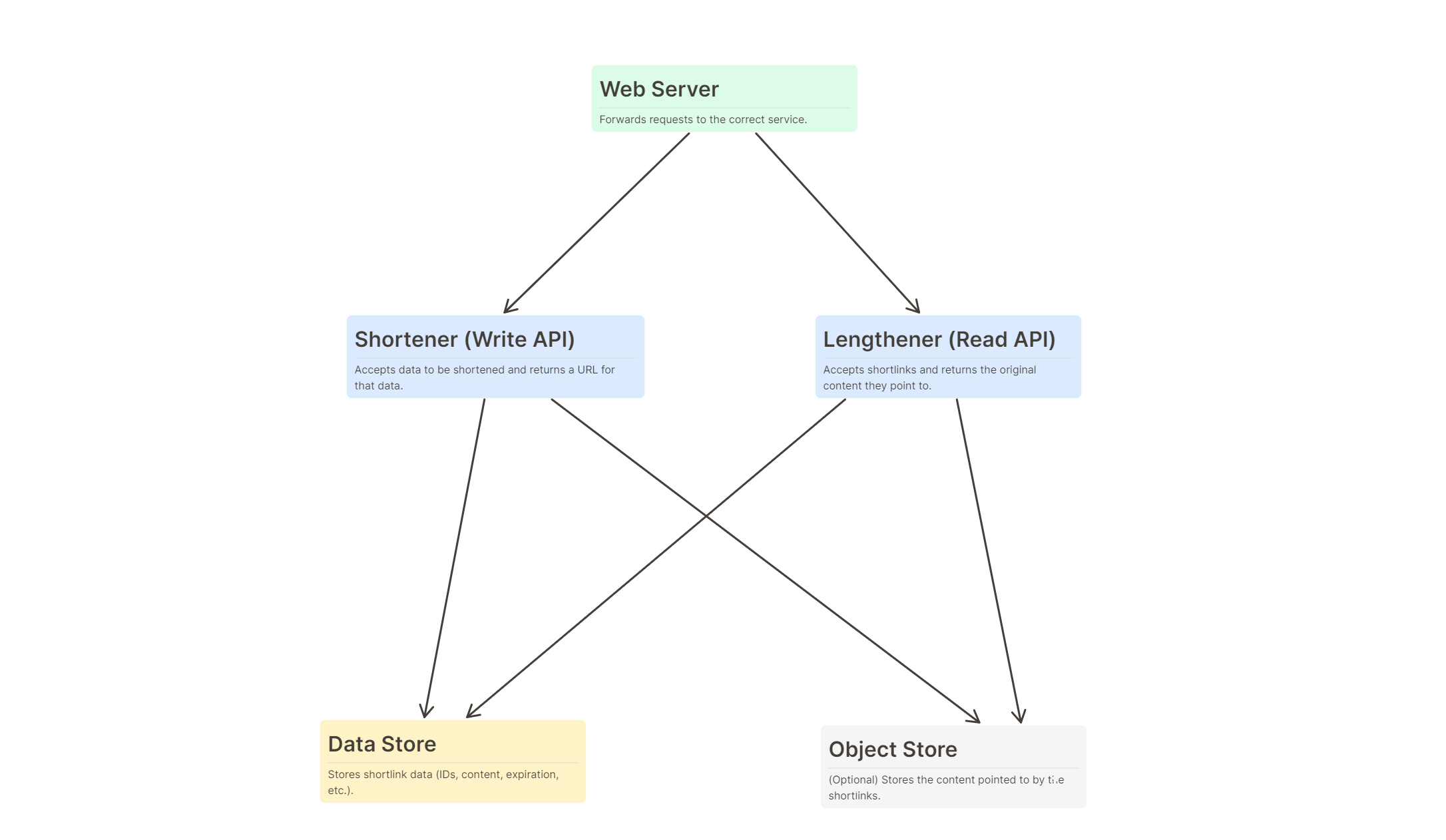
I did make some adjustments though, namely omitting the separate object store (I’m using the data store as the object store) and analytics service (I’m just writing logs to track the read/write requests). I also pared down the functionality to only this basic workflow:
submit content → retrieve a shortlink → submit shortlink → retrieve content
I’ll link you to the GitHub repo for the project for an explanation of each of the parts since I want to use this space to discuss some highlights and other things I’ve learned while working on the project.
Docker
Here’s a reusable template that’ll work for 80% of your projects. Replace <Project> with the name of your project. This assumes that the docker build context points to your solution directory (ie. the directory containing your .sln file).
FROM mcr.microsoft.com/dotnet/sdk:5.0 AS build
WORKDIR /src
COPY ./<Project> ./<Project>
# COPY other projects as needed...
RUN dotnet restore "<Project>/<Project>.csproj"
# Restore other projects as needed...
WORKDIR "/src/<Project>"
RUN dotnet build "<Project>.csproj" -c Release -o /app/build
FROM build AS publish
RUN dotnet publish "<Project>.csproj" -c Release -o /app/publish /p:UseAppHost=false
FROM mcr.microsoft.com/dotnet/aspnet:5.0 AS final
WORKDIR /app
EXPOSE 80
EXPOSE 443
COPY --from=publish /app/publish .
ENTRYPOINT ["dotnet", "<Project>.dll"]
Maybe I’ll publish this as a Gist or something.
Kubernetes
The main goal I wanted out of this project was to be able to set up my own Kubernetes cluster on my own. Up to this point, I’ve only ever been copying the manifests given to me, and I wanted to try and write some of my own. My knowledge of Kubernetes going into this was only very high-level, and I could have benefited from learning how everything works a little deeper. I’ll be focusing on that going forward. What I did learn was that the Ingress resource does provide some basic routing capabilities, so I could use that instead of a dedicated API gateway or reverse proxy. Luckily, the configuration for such an Ingress was quite simple as well:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: pastebin
spec:
ingressClassName: nginx
rules:
- http:
paths:
- path: /shorten
pathType: Prefix
backend:
service:
name: shortener
port:
number: 80
- path: /lengthen
pathType: Prefix
backend:
service:
name: lengthener
port:
number: 80
If you’re using Kubernetes on Docker Desktop, you will also need to deploy an ingress controller (note that this answer uses an old manifest). If you’re using WSL2, you may also need to go inside the WSL virtual machine in order to find the IP address of your ingress.
SQL Server
Setting up SQL Server was one of the harder parts of this project. I’ve worked with T-SQL in one of my previous university courses, but never actually learned about SQL Server itself, so I was flying blind here. That, also coupled with my cursory knowledge of EF Core made things a little difficult. In spite of this, I think I managed to come up with a pretty nice solution for deploying my database.
From what I could tell, there isn’t any explicit solution for applying my migrations to my SQL Server deployment short of reaching inside the container and executing my SQL script from there. I’ve found a couple of solutions for doing this, but they all have their drawbacks:
- Runtime Migrations - Doesn’t scale well when you have multiple copies of your application trying to apply migrations.
- Init Containers - Have similar issues to the above since you may have many replicas running copies of the same init container. This is a potentially viable solution though since it is recommended you use only a single SQL Server instance when deploying.
- Kubernetes Jobs - This is theoretically the best solution since you can guarantee that your migrations are only applied once, but requires a little bit of hacking around to have your other containers to wait for the job to finish. I avoided this solution simply because it seemed too complex for what I needed, but I’d like to revisit it when I’m more comfortable with Kubernetes.
Upon further research, I found that the official SQL Server image supports initialization from a SQL script, which means that this will play well with EF Core since the recommended way to deploy migrations to a production database is by generating SQL scripts. This solution isn’t perfect, as I still needed to make a few changes.
First, the mssql-customize repo doesn’t work out of the box, and has several open issues and pull requests to address this. I have the working Dockerfile and configure-db.sh script up on my repo.
Second, the script generated using dotnet ef migrations script needed a small preamble in order to be executed correctly:
CREATE DATABASE Pastebin;
GO
USE [Pastebin];
GO
-- Needed to create indexes.
SET QUOTED_IDENTIFIER ON;
SET ANSI_NULLS ON;
Of course, I could have opted to write the SQL myself, but if I could have it generated for me, why not use that?
The only other drawback I found with this approach was that if I deleted and recreated my SQL Server instance, the setup script would return some errors saying the tables already existed (because they were written to persistent volumes, which don’t die with the pod?). This wasn’t too much of an issue for me since no tables were being edited, and could easily be rectified with some IF NOT EXISTS statements, or even by checking for the tables in the configure-db.sh script.
Reflection
In total, this project took ~32 hours over 21 days to complete. This was slower than my most recent textbook reading, but still faster than average. Ideally, I’d like to hit a 1-2 week turnaround time for my projects, not for any particular reason other than to get in the habit of shipping. Although this project did take longer than I would have liked, I feel that there was still a lot more room to improve and that the time spent was in service of something useful. I need to get better at realizing when I’ve been spending too much time on a problem, and I need the discipline to bail and switch to the next easiest/quickest solution when something proves to be a little more work than expected. An example of this was when I was trying to write the Base62 encoder for the Shortener service. I initially used an encoder written by ChatGPT that looked good on the surface and passed all the tests I came up with, but seemed to fail often and unpredictably in production. Only after a few hours of static review and writing logging statements did I actually use the debugger to find the issue, which was not going to be an easy fix. What I should have done from the beginning was drop that code entirely and use one of the several available Base62 encoders out there.
This project was an experiment in trying to wean myself off of textbooks as my primary source of knowledge. In that regard, I believe this was a great success. I found that a lot of the questions I had could easily be answered by skimming the first few results on Google, and for anything nontrivial and out of my current knowledge, I could depend on a mix of ChatGPT and Google to come up with a solution that I somewhat understood. In the course of building this project, I wrote down almost all the issues I ran into, even the smaller ones, as well as the answers I found for them (with resources and examples). This was originally meant to serve as a sort of issue tracking/project management system to record of what I was working on since my last session, but I realized that these questions were more valuable than that. They represented pretty much everything I learned while making the project, much more deeply than what I would normally put in these writeups. I’ll write down my thoughts about this process in a separate post though.
This was the first of many system design projects, and I’d like to eventually go through all of them if I don’t find anything better to do. That being said, I’d actually like to hit up the textbooks again to fill in the gaps found while making this project. At least I know what to look for this time and what to avoid from last time.