This project was made to accompany my reading of Hands-On Software Engineering with Golang. Please note that the vast majority of this code was not written by me, however I did make a couple of meaningful changes: (1) I reorganized all the packages into a form I liked better (similar to the Standard Package Layout), (2) I rewrote a few of the tests (add links) to use the standard testing package rather than GoCheck, and (3) I got rid of a lot of old/deprecated code since the project isn’t exactly up-to-date. Here is a(n incomplete) list of notes I made while editing the codebase:
- The CockroachDB DSN for the
migratetool is different from the DSN expected by the code. - The Elasticsearch cluster needs its security disabled. Add this to your
elasticsearch.yml:xpack.security.enabled: false - The Elasticsearch package needs to be versioned.
- A lot of the protobuf installations were deprecated. I found new installs and packages.
- The
protocinvokation needed to be updated, and theoption go_package = "..."line needed to be added to my.protofiles. - The
proto.Unimplemented*Servertype needed to be embedded in the server implementations. - The code uses the deprecated
ptypespackage. I have replaced most of these calls with their respectiveproto,anypb, andtimestamppbfunctions.
I did end up downloading GoCheck just to see how it works, and I found it to be quite nice for testing, especially since GoLand supports it out of the box.
I did make refactorings to the code to make it more readable to me and rewrote some pieces of code into my own style, but ultimately I didn’t feel like I could easily modify the business logic as I wanted to. Despite this, I did manage to get some level of familiarity with most parts of the project (I skipped the discussion on the PageRank calculator), and can reasonably understand what each line of code does. Unlike in the Let’s Go and Let’s Go Further books, not all pieces of code in the project were explained. Most of the code was commented, but it still took a few rereads to understand what was going on and why.
You can find the original code repository here: https://github.com/PacktPublishing/Hands-On-Software-Engineering-with-Golang, and my version here: https://github.com/ejacobg/links-r-us. Note that not all packages and tests defined in the original repository were ported over into my version. Some packages were simply demos of the concepts discussed in the book.
Disclaimers
Kubernetes
I tried very hard to fix up the Kubernetes Makefile targets as best I could, but I ended up running into a bunch of problems simply because I used different versions of practically every piece of software that was used. Even then, I would have some of my pods going down and my Docker repository not responding, so not everything can be blamed on versioning issues. If you’re reading this book for the first time, you should copy the same setup as the author since that’s the only guarantee that things will work right the first time. The project does work when running it locally though. I’ll keep fiddling with the Makefile, but for now be warned that it doesn’t work (at least on my computer).
I copied over the Kubernetes manifests and Makefile targets for the distributed version of the program, however I did not make any changes to them. I wasn’t able to get the monolithic version working, so it wasn’t worth trying to get the distributed version working either. Everything after chapter 10 was ported over as-is since I was not able to experiment with it much without the Kubernetes cluster.
The BSP Model
I skipped pretty much the entirety of the discussion on the Bulk Synchronous Parallel (BSP) model (chapters 8 and 12) because it simply wasn’t relevant to my goals for the project. I pretty much just ported over the code without really looking at it. The code from chapter 12 was omitted entirely.
Overview
The program makes use of several core components.
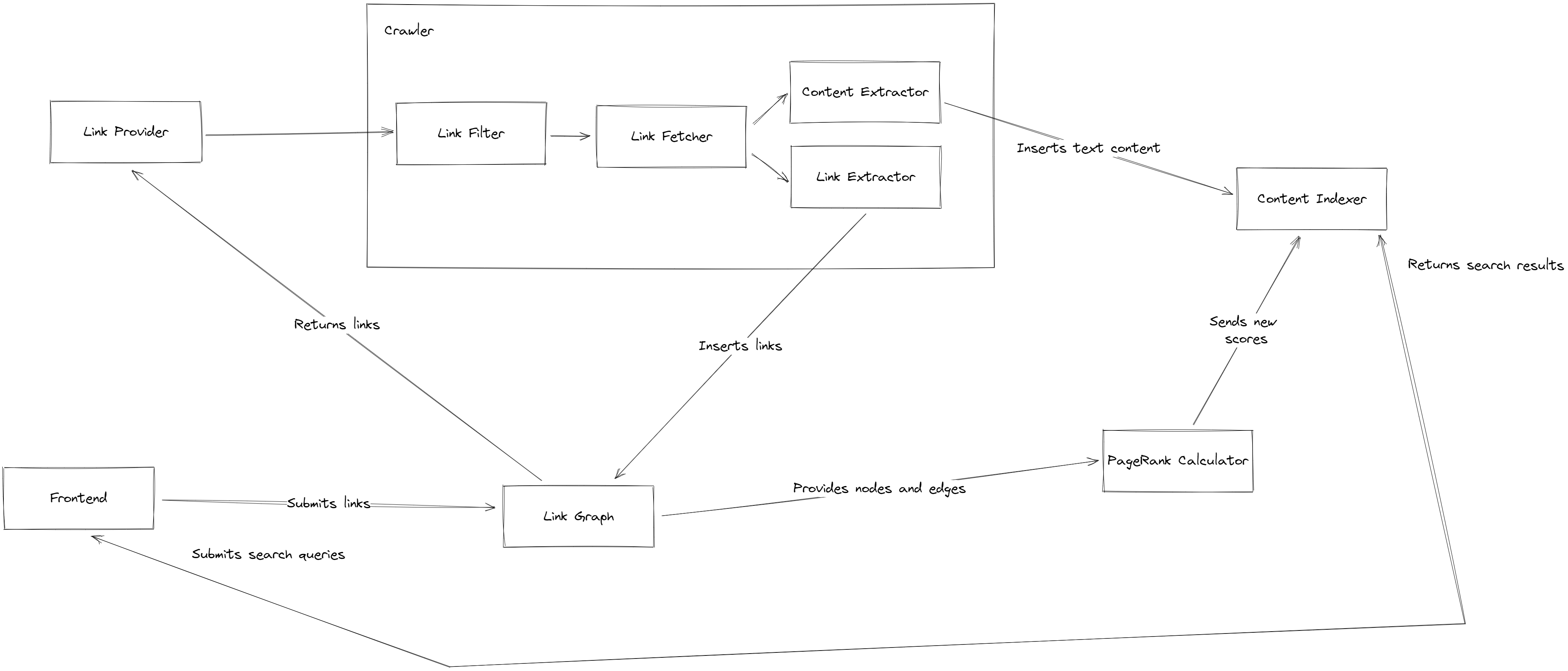
The Frontend handles all user interaction. It allows users to submit new links for the crawler to fetch and index, and provides a search box to submit queries and view their results.
The Link Graph stores all the links used by the program. It also stores directed edges showing which URLs contain links to other URLs. The Link Graph provides methods for other components to query and modify the graph. Links submitted by the frontend are inserted into the Link Graph.
The Link Provider represents a source of links that will be fed into the crawler pipeline. The Link Graph implementation is typically acts as the Link Provider.
The Crawler takes in links from the Link Provider and processes them using several subcomponents.
- The Link Filter determines the content type of a link, and will reject al links it thinks the system cannot process (eg. images or videos).
- The Link Fetcher takes all filtered links and makes an HTTP request to the remote server, following any redirects and checking that the
Content-Typeheader is something the system can process. - The Content Extractor extracts all text content from a document. This supports both plaintext and HTML documents.
- The Link Extractor will identify and extract all links present on an HTML document.
The Content Indexer maintains a full-text index of the content emitted by the Content Extractor, and also provides methods for other components to access the index.
The PageRank Calculator takes a snapshot of the graph, then uses it to calculate a PageRank score. These scores will then be written back into the Content Indexer to be used when querying.
The Link Graph is initially empty, and can be populated by the user through the Frontend. Periodically, all the links in the Link Graph get run through the Crawler in order re-index their content. Any new links discovered by the Crawler also get sent back to the Link Graph to be crawled in the next pass. The PageRank calculator also runs periodically so that changes to the graph are reflected with their new scores.